
Lamb: my upcoming selfhosted microblogging service
Started a new project called Lamb:
Literally Another Micro Blog.
Barrier free super simple blogging.
- sqlite based
- twitter like interface
- register to a flock, index of blaats
Started a new project called Lamb:
Literally Another Micro Blog.
Barrier free super simple blogging.
- sqlite based
- twitter like interface
- register to a flock, index of blaats
So, I’m building a digital card game… (Follow https://2022.vandragt.com/category/project/ if you want to read my devlog).
Fafi developer builds can now index individual urls, and extract urls from text based files (such as .html). That should make it more interesting if you want to search page content but don’t use Firefox.
Search Firefox bookmark contents, with this commandline client. Fafi extracts the page content of bookmarks and stores them into a searchable SQLite database.
fafi.pex file from the terminal.You can download the pex file, or use pipx install fafi (requires pipx), and run it.
I have recently been interested in using HTMX, but there’s not been any activity within the WordPress community as far as I can see. I hope to change that with HTMXpress (pronounced as HTM express).
HTMX allows you to annotate dynamic script style behaviour via custom HTML properties, using progressive enhancement. Perhaps you’re familiar with Hotwire (ruby on rails) or Intercooler.js (htmx predecessor).
By using the Rewrite Endpoints API to create a custom endpoint; and a bit of custom template logic, we can output a serverside partial or custom theme template.
Using this setup, WordPress can leverage HTML over the wire solutions such as HTMX.
HTMX then allows us to do dynamic serverside based rendering; live search and other features without the overhead and complexity of reactive JavaScript frameworks, whilst benefiting from trusted object and full page caching solutions.
Currently it’s a prototype. I’ll be blogging more about progress as things go on.
I tested and created a IFTTT recipe for backing up Liked Songs’ tracks : https://ifttt.com/applets/iMnNGt3V-backup-spotify-likes.
Despite the incorrect labelling “Saving a spotify track” means liking it, not “downloading to your device”. So you can add it to another Spotify playlist.
To get historical likes, cmd-a / ctrl-a (or equivalent) all Liked Songs tracks and drag them into the backup playlist.
This enables playlist options such as Playlist Radio giving you similar songs to the ones in the backup playlist.
I’ve been switching my local WordPress sideprojects development setup to VVV and one thing I couldn’t find documented is how to setup ElasticSearch and ElasticPress.
There’s a VVV-ElasticSearch plugin on GitHub but it is missing documentation and it’s not been updated for 6 years :D), so I made my own:
Today, I setup my Xbox 360 in order to play some audio cds 🙈😂
So I spent most of the evening adding drag and drop physics to a card sprite and moving it around. I fairly underestimated the amount of learning required to use this game engine!
I’ve released Psh 0.3.0, my php subshell. Tired of switching tooling versions between PHP projects? Psh starts a shell with your project requirements linked ready to go.
As a macOS user with a multi monitor setup and a laptop I frequently switch between 1 to 3 screens. I use task related spaces (general, coding, organisation, social) and to reinforce this habit I installed some Unsplash wallpaper images relating to the task.
In some undefined situations I lose the wallpaper image on certain screens on certain desktops (I have already disabled reordering and removing spaces) but dragging wallpapers across multiple screens on multiple spaces is too much work; and why not see if this can be automated.
Thanks to Hammerspoon and a few minutes time you can benefit from my script:
-- SYNC WALLPAPER --
function sync_wallpaper()
wp = hs.screen.primaryScreen():desktopImageURL()
for index,screen in ipairs(hs.screen.allScreens()) do
if screen:desktopImageURL() ~= wp then
print('Syncing Wallpaper')
screen:desktopImageURL(wp)
end
end
end
hs.spaces.watcher.new(sync_wallpaper):start()
-- /SYNC WALLPAPER --Add this to your .hammerspoon/init.lua and switch spaces to sync wallpapers to all screens on that space!
I’m using the following wallpapers:
Cuttlefish simplifies creating and deploying PHP websites. In version 0.6 this focus continues by simplifying tooling friction and making routing and controllers more powerful.
This is a script for Hammerspoon that reorders the windows on the current screen in a reverse cascade, with the active window at the front left. It’s very useful to view all windows at once and create order from a mess of windows.
The name refers to the shortcut used to perform the action: control-option-command+/. This shortcut is editable in the script.
I’ve released Taskfile 1.1.0, with the following changes:
Taskfile remembers how to run all your shell based workflows.
Taskfile is now in maintenance-mode, so I can focus on other projects, as there are no feature requests 👍
Taskfile runs task files, a bash (or zsh etc.) script that contains functions that can be called via the runner. These files must be called .Taskfile. The runner detects any taskfiles in the current, parent, grandparent etc directory of the directory you’re in.
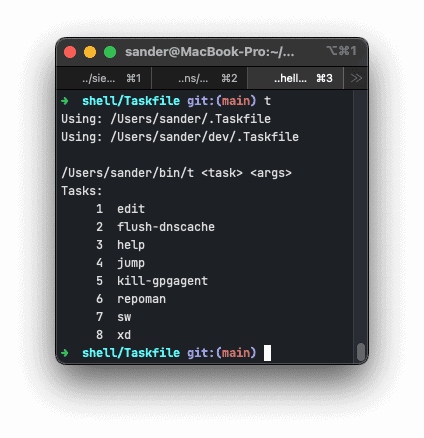
I’ve refined the edit task that ships with the script so that it opens the .Taskfile in the current directory if it exists, before falling back to editing the runner.
I often use my side projects for experimenting with concepts and one area of interest is onboarding. Too often there are major hurdles and complexities in getting started contributing or developing web projects.
With Cuttlefish the goal is to be as approachable as possible and be productive after running a single command.
So I’m happy to say today I landed a few PRs in the main branch that add zero configuration project tooling in the guest when using vagrant🎉
Dependency management, linting, pre commit hooks etc are all ready to go after a vagrant up. I’m pretty chuffed.
It’s optional so you can still bring your own tooling and use the built in PHP webserver.
Hopefully that should make it easy to get up and running and contribute.
Cuttlefish is my hackable web/blog framework. I’m doing most of the hacking and eventually you might blog.
Rubber ducking a bit. Working on the coupling of the controller name being linked to the content structure. For example /posts/x loads the post controller with the post model and content from content/post/x.md.
It felt intuitive but I’m not happy deriving a path literally from a class name. In Particular the post archive is an archive controller with a post model. Also feeds/post vs feeds/auctions or something.
Originally I went with contentpath being based on a controller name property. But because the model already specifies the fields available in the content that didn’t seem right
So doing some work around each model having a content path property but not 100% if that’s the right relation.
Feels like It’s doing two things. Routing and content types.
For instance if I want a /blog I’d probably create a blog controller with a post model with records loaded from content/blog.
Looks like the controller is registered to a path via the router and it dictates the content path after all.
Search Firefox bookmark contents, with this commandline client. Fafi extracts the content of the bookmarks and stores them into a searchable SQLite database
This latest personal site design iteration improves the reading experience.
Post margins are condensed and subtle delineation guides the eye. The byline, categories and tags post meta are now hidden on the homepage, reducing clutter. I highlighted hovered articles for clarity.
Please visit and feedback.
Delete your old tweets with Twelete, my new release https://github.com/svandragt/twelete.
Tweets are temporary messages, and thus others should not keep your tweets. You have the right to be forgotten, without paying for the privilege.
Set this up on a cheap VPS; Raspberry PI, or locally. Feedback welcome!