I use the following script to run a daily upgrade on the #BookStack instance:
#!/usr/bin/env bashpushd /var/www/brain.vandragt.com git pull origin release && composer install --no-dev && php artisan migrate --forcepopd

Senior Web Engineer. Open web / music. Remote DJ. Tall Dutch guy. #3million
I use the following script to run a daily upgrade on the #BookStack instance:
#!/usr/bin/env bashpushd /var/www/brain.vandragt.com git pull origin release && composer install --no-dev && php artisan migrate --forcepopd
I'm looking to create a cross-platform executable of my commandline application. The application is using poetry as the package manager, and I'm running this on MacOS.
First we need to install PyInstaller:
$ poetry add pyinstaller --dev
Then it should be as simple as running the following:
$ poetry shell
$ pyinstaller --onefile app/app.py
However, this resulted in the following error:
ModuleNotFoundError: No module named 'macholib'
macholib can be used to analyze and edit Mach-O headers, the executable format used by Mac OS X.
It’s typically used as a dependency analysis tool, and also to rewrite dylib references in Mach-O headers to be @executable_path relative.
Manually adding this dependency to the project addresses this:
$ poetry add macholib --dev
However, now calling pyinstaller again throws up a new error:
Unable to find "nltk_data" when adding binary and data files.
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries [...].
Fortunately we can download the missing data as follows (from within the poetry shell):
$ python
>>> import nltk
>>> nltk.download()Press the download button on the window that pops up and make sure the installation path matches the error message path.
Then fix the path to NLTK in PyInstaller according to this StackOverflow answer. To get to the right location, ask poetry:
$ poetry env list --full-path
$ cd <path>/lib/python3.7/site-packages/PyInstaller/hooksRerunning the pyinstaller command after this produced an executable! However it's 1.2GB, propably due to including the macholib library.
I will update this post when I've figured this out.
Hide Trackbacks is a WordPress plugin that hides pingbacks and trackbacks from your website comments.
The minimum supported WordPress version is now 5.0 and I've bumped up the version to indicate it is tested against the upcoming 5.4 release.
I just released Fafi v0.1.5-alpha. Fafi is a console application that indexes and searches the page content of Firefox bookmarks.
Install via pipx install fafi
v0.1.5 stores the database into it's own application settings (using https://
I run my own Nextcloud server, and every other week there's an update to the server, or one of the plugins I've enabled. The following steps enable automatic updates to the Nextcloud server.
This assumes Nextcloud is installed under /var/www/nextcloud:
Add a scheduled task as the webserver user:
$ sudo -u www-data crontab -e
Add the following line to run the upgrade script once a day at 4:05am. Instead of running the upgrade process directly we run a script so that we can also run it from the shell if needed:
5 4 * * * cd /var/www/nextcloud && ./upgrade.shNow create the script and make it executable:
$ cd /var/www/nextcloud$ nano upgrade.sh && sudo chmod +x upgrade.sh
The script itself runs the server updater, the no-interaction argument prevents prompting for questions, followed by the occ utility to update all installed apps.
pushd $(dirname $0)/updater
/usr/bin/php updater.phar --no-interaction
cd ..; ./occ app:update --all
popd
Over the holidays I’ve build a little tool, Faff, to index and search the page contents of Firefox bookmarks. This allows searching using words that appear on the pages rather than in the bookmark title. It uses full-text-search with ranking / relevance and snippets, it’s quite WIP. More info at https://

It's written in Python command-line tool and uses SQLite's full-text search and Newspaper's text extraction, so a search over all my bookmarks takes only about 0.3 seconds although the indexing is certainly slow.
#faff #projects
Cuttlefish is a PHP based hackable blog framework -- with the goals of being fast, easily hackable, and easy to adopt. I've been working on it since 2012, when it was known as Carbon. It can generate a static HTML site for uploading anywhere, or run dynamically.
Version 0.4 licenses the code as MIT, so anyone can build on top of the project. Cuttlefish now has API documentation courtesy of PHPDox, which is updated whenever code is changed. I've changed the code style from 'WordPress-like' to the PHP community default of PSR12. The project now comes with a Docker container which means getting up and running is even easier.
Install Cuttlefish is easy using the instructions. For a fuller list of changes see https://
Known issue: I still have trouble getting Xdebug to work, if you're familiar with Docker Compose and Xdebug I could use your help.
For v0.5, now that the codebase is in a better state, I'm looking at adding more features again.
Add the following lines to ~/.gitconfig to load configuration only for repositories within a certain location:
[includeIf "gitdir:~/dev/work/"]
path = ~/dev/work/.gitconfig
For example, this can be used to set work email and signing keys.
If you follow this blog you will have noticed that I've commented multiple times on needless distractions that seem to have pervaded modern computing. Today, let's present a few solutions.
Firstly, when in the flow of doing deep work, watching animations delay your actions can be a source of frustration. While we can't speed up GitHub, we can speed up macOS. In the accessibility settings, check Display > Reduce Motion. This will speed up the interface and Mission Control animations. If you miss the garishness, you can turn it back off but chances are you will notice the system not getting in the way as much.
Secondly a tip for fellow Homebrew users. When you're ready to work through that difficult project tooling setup, it can be the worst time for Homebrew to decide to update it self, especially as this can take up to half a minute depending on how far behind your version is. Not now Homebrew! If you follow the instructions at Homebrew Autoupdate you can setup Homebrew to update itself in the background.
Finally, if you're using oh-my-zsh or bash equivalent, there will be a setting for it to update itself without prompting. Edit .zshrc and add DISABLE_UPDATE_PROMPT="true". I've not had any issues.
Cheers to a focused work experience!
Unless you're using DNS over HTTP (DoH), you can speed up general DNS requests by running a local DNS proxy, and increase the expiry time of DNS queries. I'll go into this further once I've updated this post for DNSMASQ to do DoH.
The following configuration will speed up browsing in Safari for example.
Install DNSMASQ:brew install dnsmasq
Load all configs from /etc/local/etc/dnsmasq.d/:echo "conf-dir=/usr/local/etc/dnsmasq.d,*.conf" | sudo tee —append /usr/local/etc/dnsmasq.confmkdir -p /usr/local/etc/dnsmasq.d
Edit /usr/local/etc/dnsmasq.d/proxy.conf:# Tell dnsmasq to get its DNS servers from this config file only.no-resolv# Add router dnsserver=192.168.1.1# cache for 1hmin-cache-ttl = 3600
Start DNSMASQ on boot and launch it:sudo brew services start dnsmasq
Test: dig cnn.com @127.0.0.1
Query time should be 0 the second time and an ANSWER SECTION should be returned. If that is the case open System Preferences > Network > Advanced > DNS > +
Enter: 127.0.0.1 and hit OK > Apply.
Improvements to the Events pages are in the works for 2020, too. You’ll soon see more functionality and a new look, such as the ability to set an alert on an event you want to attend, to follow your favorite event hosts, to share your event calendar with friends, and to see the latest event developments in a news feed.
https://
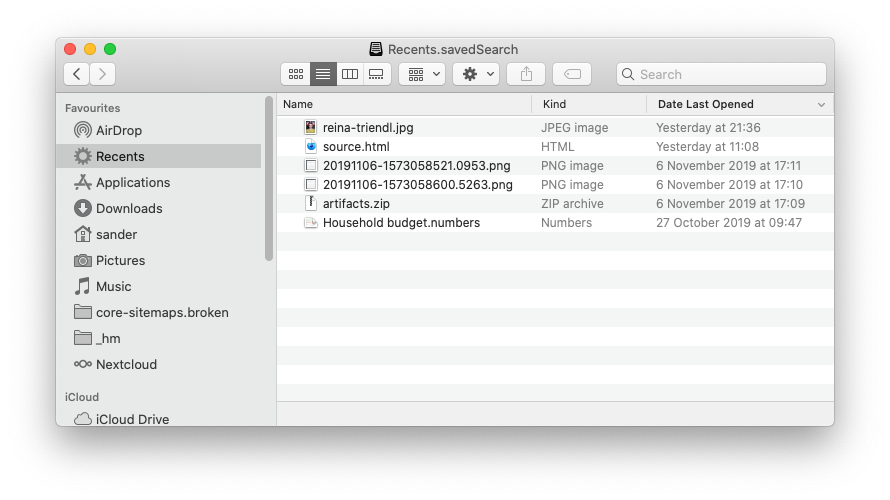
So if you open Recents in the sidebar it's likely it's full of files you have no idea you recently opened. It's most likely that you didn't. We can make Recents more useful by restricting the last opened date, and make using it more convenient. This is how:
As a bonus tip, update the icon for the smart search (just like any other folder and app) as follows:
Open /System/Library/CoreServices/CoreTypes.bundle/Contents/Resources/ and search for "Recents" to find the current Recents icon, or choose an alternative.
Right click on the My Recents icon in the sidebar and choose Get Info.
Drag the preferred icon from the folder into the icon slot in the top left of the Get Info window.
This changes the icon in the window title, but I haven't found out how to change it in the sidebar.
If you're working with two SSH keys (work / personal) then the following setup is quite elegant. It assumes all repositories are work related, unless they're hosted under your own user:
Host *AddKeysToAgent yesUseKeychain yesStrictHostKeyChecking noUser gitIdentityFile ~/.ssh/id_rsa_corporate# personal accountHost github.com-MYUSERNAMEHostName github.comUser gitIdentityFile ~/.ssh/id_rsa
A new OS, another two hours wasted. Pop!_OS 19.10 comes with Python3.7rc5, which is nice but my project requires 3.6 just now. As you know we've gone through this before, but this time we can setup multiple python version support.
Let's setup pyenv, pip, pipenv and then install another python version.
# Setup pip.
curl https://bootstrap.pypa.io/get-pip.py | python
# Pip can setup pipenv.
pip install pipenv --user# Manage multiple python versions through pyenv.
# @see https://github.com/ pyenv/ pyenv/ wiki/ Common-build-problems sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl gitcurl https://pyenv.run | bash
Follow the instructions to add pyenv to the path. Now we can do stuff like:
# install another python version.pyenv install 3.6.9# OR let pipenv do it.cd ~/dev/myprojectpipenv install --dev
Leave a comment if you have any issues, as this was written retrospectively.
I'm starting to realise how often I say good / great / well without being explicit about what I think is positive about something. Trying to replace ‘that is a good idea’ which only communicates my positive assessment with the explicit thing I appreciate so people can make their own assessment based on their values. Maybe this thought helps someone else!
I had trouble installing global npm packages, which failed due to permission errors. I don't want to use sudo as this will lead to problems later, and I don't want to set the global installation directory to a local directory, as that means other users don't have access to the packages.
As recommended by the NodeJS documentation this is best fixed by installing node via a version manager.
First, remove node which I incorrectly installed with homebrew:
brew uninstall nodeThen install nvm as per the official instructions. In my case this also failed as this is a new system that doesn't have a .bash_profile yet. Hower as I wanted to install the zsh shell, I installed oh-my-zsh as per the instructions on their site.
Once zsh was installed (or you've created a .bash_profile using touch ~/.bash_profile, you can install node in a correct manner as follows:
nvm install nodeHappy yak-shaving!
It seems today is 0.3 day, as I'm also releasing Carbon 0.3, my hackable performant semi-static blogging system.
This release mainly deals with technical debt as I first started this project 6 years ago as a playground for figuring out how a CMS is written from the ground up. This means there are out of date requirements, references to a Windows platform with Powershell and other such bad examples.
That said the codebase isn't in a terrible state although it will have to change significantly before it's production ready. If you know a bit of PHP then after a short study it can be customised to your needs quite easily.
So, if you're interested you can use it and quickly whip together a documentation or simple blog using only markdown files. It will produce a feed and there's even a half baked cli application and static site generation that I have to review before I can recommend it in honest.
Have fun hacking!
I've released Fresh Cookies 0.3, my browser extension for limiting the lifetime of browser cookies to a maximum of 15 days.
It is now a web extension and can be manually installed in Firefox (it also works in Chrome). I'm looking for feedback before I'm ready to submit it any extension directories.
Today I managed to break pipenv again to a point where I cannot install any project requirements. Let's document the process to prevent this happening again in the future.
Python3.7 and pip are already installed on OpenSUSE Tumbleweed. If you're not so lucky, read the page on https://
Instead we're going to install pipx which is best described as a per-command environment for python executables. This is great for packages like pipenv which can then run without conflicts. pipx also keeps the packages updated.
python3 -m pip install --user pipx
python3 -m pipx ensurepath
We can then use pipx to install pipenv:
pipx install pipenv
I prefer to keep the virtual environment within the project folder, by adding the following line to .bashrc or .zshrc:
export PIPENV_VENV_IN_PROJECT=1
With pipenv in place we can create a per-project virtual environment and activate it:
cd ~/dev/myproject
pipenv shell
We can install our packages into the environment now:
pipenv install pylint --dev
pipenv install black --dev --pre
The missing step in a lot of guides, is that you later might want to call your script from outwith your virtual environment, without explicitly activating it as you would do when working on the project itself. You can do that thusly:
$(pipenv --venv)/bin/python myscript.py
So ehm... when a person requires the NHS emergency services post Brexit, how do the staff know that a person is an EU citizen that might requires an online settled status check (which in turn requires a passport, identity card or biometric residency card) and not a UK citizen which doesn't need to (and can't) be checked? If we exclude all measures that are discriminatory?
So either all UK citizens also take their passport with them going forward as well; or this is going to end in discrimination for people including, but not limited to, those with an accent, "look foreign", UK citizens that've lived or studied abroad (affecting their speech), people speaking another language, or any other identifying marks or clothing.
As not all UK citizens have passports however, the NHS cannot use the Home Office provided website to rule out they're an EU citizen. That's just as well as the website doesn't work for UK nationals, it would only tell them they don't have settled status.
As a result this makes the process essentially voluntary for people who self identify as an EU citizen and want to be discriminated against.
Hey where are you from? London. You don't sound British? I was born in England but studied in Amsterdam.
The process isn't fit for purpose.